事件循环
Event Loop 是一种运行机制。
宏任务macrotask和微任务microtask两个概念,这表示任务的两种分类。
在挂起任务时,JS 引擎会将所有任务按照类别分到这两个队列中,首先在 macrotask 的队列(这个队列也被叫做 task queue)中取出第一个任务,执行完毕后取出 microtask 队列中的所有任务顺序执行;
之后再取 macrotask 任务,周而复始,直至两个队列的任务都取完。
V8引擎
V8引擎基本概念关系图 (根据 Google V8 官方文档)
http://imagesrc.oss-cn-shenzhen.aliyuncs.com/notes/201809281123.jpg
handle
handle 是指向对象的指针,在 V8 中,所有的对象都通过 handle 来引用,handle 主要用于 V8的垃圾回收机制。
上下文(context)
context 是一个执行器环境,使用 context 可以将相互分离的 JavaScript 脚本在同一个 V8 实例中运行,而互不干涉。在运行 JavaScript 脚本是,需要显式的指定 context 对象。
运行时概念
可视化描述
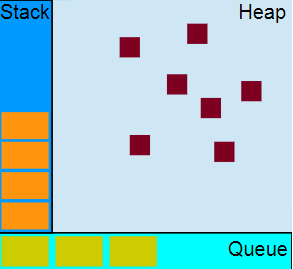
栈
函数调用形成了一个栈帧。
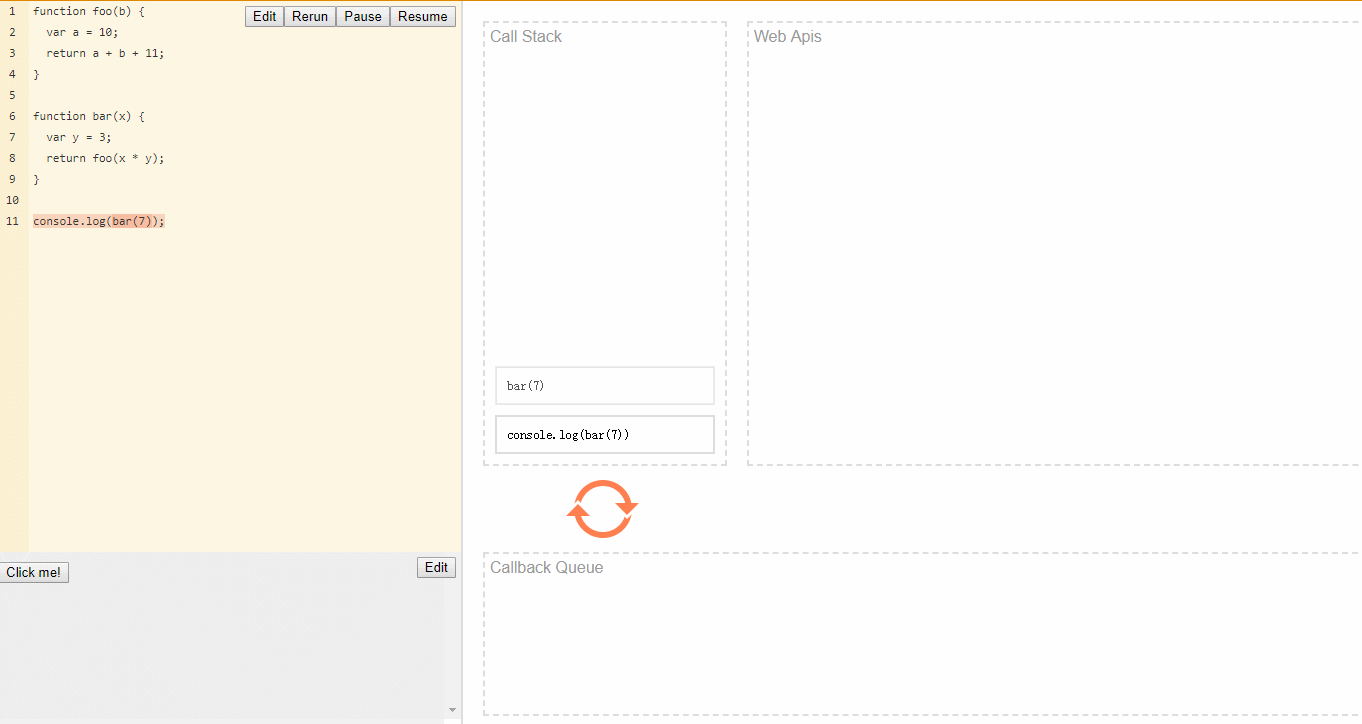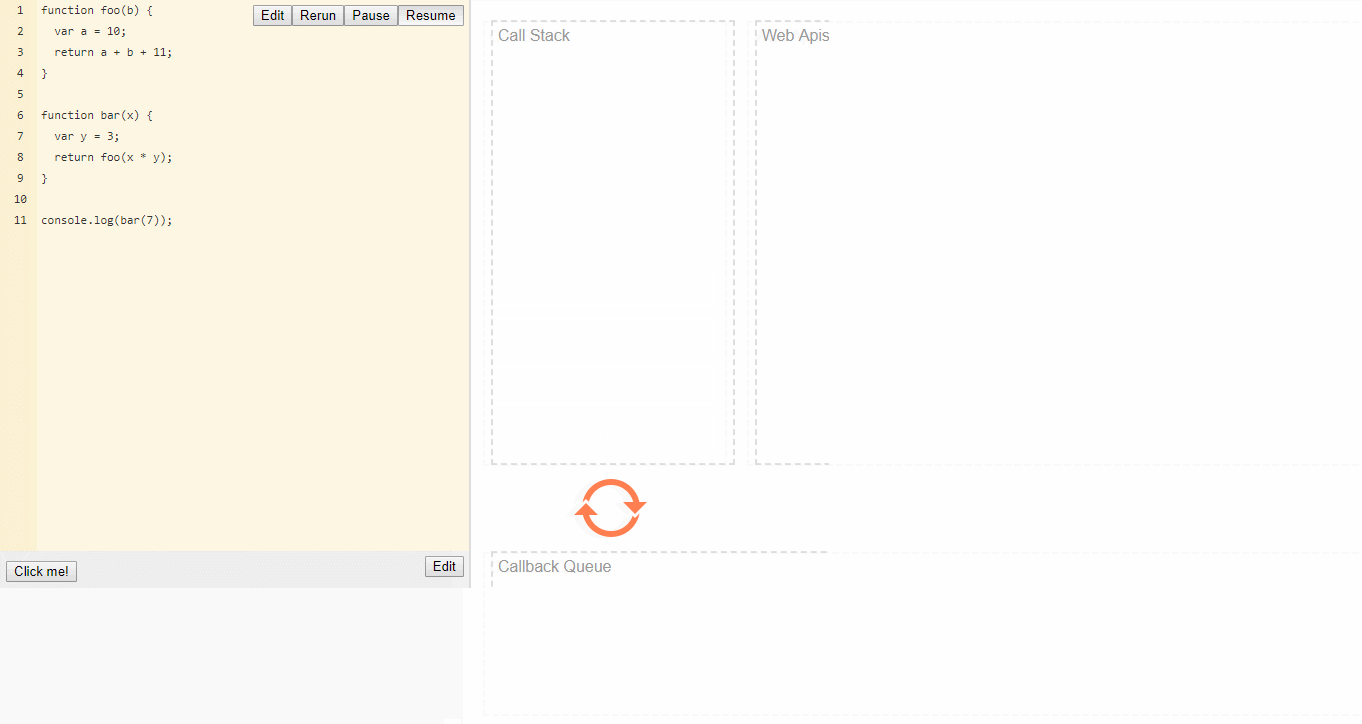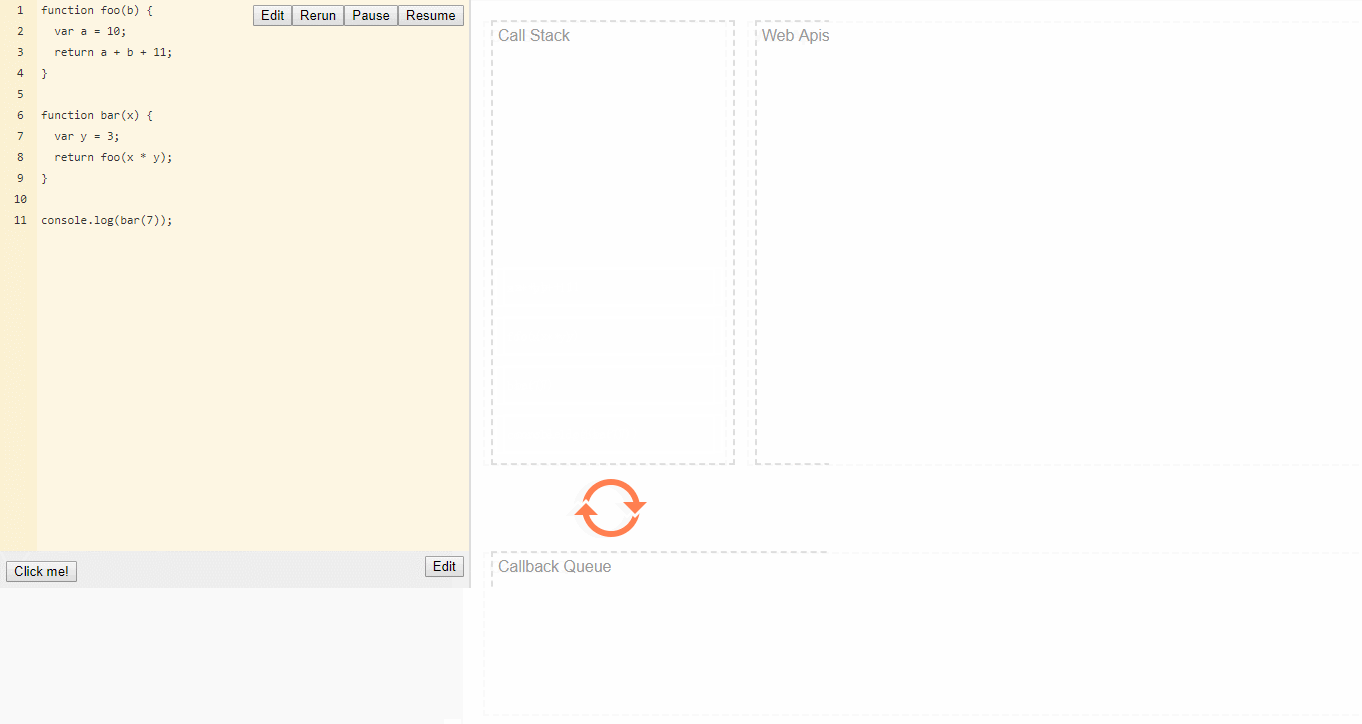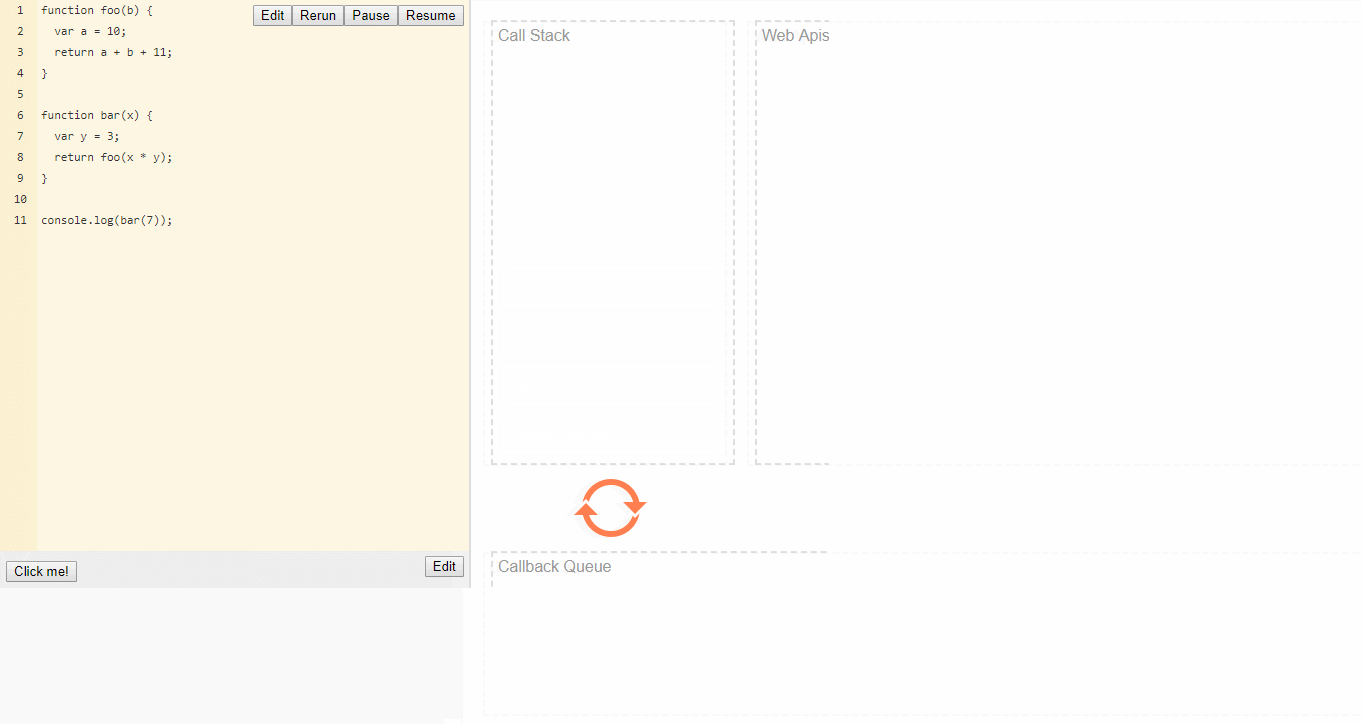
1 | function foo(b) { |
当调用bar时,创建了第一个帧 ,帧中包含了bar的参数和局部变量。
当bar调用foo时,第二个帧就被创建,并被压到第一个帧之上,帧中包含了foo的参数和局部变量。当foo返回时,最上层的帧就被弹出栈(剩下bar函数的调用帧 )。
当bar返回的时候,栈就空了。
堆
对象被分配在一个堆中,即用以表示一个大部分非结构化的内存区域。
队列
一个 JavaScript 运行时包含了一个待处理的消息队列。每一个消息都有一个为了处理这个消息相关联的函数。
在事件循环期间的某个时刻,运行时总是从最先进入队列的一个消息开始处理队列中的消息。正因如此,这个消息就会被移出队列,并将其作为输入参数调用与之关联的函数。为了使用这个函数,调用一个函数总是会为其创造一个新的栈帧,一如既往。
函数的处理会一直进行直到执行栈再次为空;然后事件循环将会处理队列中的下一个消息(如果还有的话)。
浏览器事件循环
事件循环(WHATWG规范)
要协调事件(event),用户交互(user interaction),脚本(script),渲染(rendering),网络(networking)等,用户代理(user agent)就需要使用事件循环(event loops)。
有两种事件循环:
- 用于浏览器上下(
browsing context)文的事件循环 - 用于
workers的事件循环
事件循环机制
一个事件循环有一个或多个任务队列(
task queues),一个任务队列是有序列表的任务,这些算法负责以下工作:
事件(Events),解析(Parsing) ,回调(Callbacks),使用资源(Using a resource),对DOM操作做出反应(Reacting to DOM manipulation)每个任务都定义为来自特定任务源
task source。必须始终添加来自一个特定任务源并发往特定事件循环的所有任务(例如,由Document的计时器生成的回调,针对该Document的鼠标移动而触发的事件,排队等待该Document的解析器的任务)到同一任务队列,但来自不同任务源的任务可以放在不同的任务队列中。例如,用户代理可以为鼠标和键事件(用户交互任务源)创建一个任务队列,为其他所有事件设置另一个任务队列。然后,用户代理可以在四分之三的时间内为其他任务提供键盘和鼠标事件首选项,保持界面响应但不会使其他任务队列处于饥饿状态,并且永远不会无序地处理来自任何一个任务源的事件。
每个事件循环都有一个当前运行的任务。最初,这是null。它用于处理重入。每个事件循环还具有执行微任务检查点标志(
microtask checkpoint flag),该标志最初必须为假(false)。它用于防止执行微任务检查点算法的重入调用。
事件循环处理模型
一个事件循环存在,将连续执行以下步骤:
- 选择最先进入事件循环任务队列的一个任务(
oldestTask), 如果队列中没有任务,则直接跳到第6步的microtask - 将事件循环的当前运行任务设置为上一步所选择的任务(
oldestTask) - 运行所选任务(
oldestTask) - 将事件循环的当前运行任务设置为
null。 - 从其任务队列中移除
oldestTask。 - 微任务(
microtask):执行微任务检查点 - 更新渲染(
update the rendering) - 如果这是一个
worker事件循环(即一个为WorkerGlobalScope运行的循环) - 跳到第一步
微任务(microtask)
每个事件循环都有一个微任务队列。微任务是最初要在微任务队列上排队的任务,而不是任务队列上排队的任务
当算法需要对微任务进行排队时,必须将其附加到相关事件循环的微任务队列中;这种微任务的任务源是微任务任务源
当用户代理要 执行微任务检查点 时,如果执行微任务检查点标志为false,则用户代理必须运行以下步骤:
- 将执行微任务检查点标志(
flag)设置为true。 - 而事件循环的微任务队列不为空:
- 让
oldestMicrotask成为事件循环的微任务队列中最老的微任务(oldest microtask) - 将事件循环的当前运行任务设置为
oldestMicrotask - 运行
oldestMicrotask - 将事件循环的当前运行任务设置为
null。 - 从微任务队列中删除
oldestMicrotask。
- 让
- 对于其负责事件循环是此事件循环的每个环境设置对象,请通知该环境设置对象上被拒绝的承诺。
- 清理索引数据库事务。
- 将执行微任务检查点标志设置为
false。
微任务的实现:
process.nextTick:事件循环的下一次循环中调用callback回调函数Promises:Promise对象用于表示一个异步操作的最终状态(完成或失败),以及其返回的值。Object.observe:Object.observe()方法用于异步地监视一个对象的修改MutationObserver:(Mutation Observer API用来监视DOM变动)
宏任务(macrotask)
宏任务的实现:
script(整体代码)setTimeoutsetIntervalsetImmediate:该方法用来把一些需要长时间运行的操作放在一个回调函数里,在浏览器完成后面的其他语句后,就立刻执行这个回调函数,I/OUI rendering
测试代码
1 | console.log("script start"); |
chrome执行顺序:
script start、script end、promise1、promise2、setTimeout
nodejs事件循环
nodejs的event是基于libuv
事件循环允许Node.js执行非阻塞I/O操作
尽管JavaScript是单线程的,通过尽可能将操作卸载到系统内核。
由于大多数现代内核都是多线程的,因此它们可以处理在后台执行的多个操作。 当其中一个操作完成时,内核会告诉Node.js,以便可以将相应的回调添加到轮询队列中以最终执行。
事件循环
当Node.js启动时,它初始化事件循环,处理提供的输入脚本(或放入交互式解释器(REPL)),这可能会进行异步API调用,调度计时器或调用process.nextTick, 然后开始处理事件循环。
事件循环操作顺序:
注意: 以下每个框都将被称为事件循环的“阶段”
1 | ┌───────────────────────────┐ |
每个阶段都有一个要执行的回调先入先出(First Input First Output)队列。虽然每个阶段都有自己的特殊之处,但通常,当事件循环进入给定阶段时,它将执行特定于该阶段的任何操作,然后在该阶段的队列中执行回调,直到队列耗尽或执行的回调的最大数量为止。当队列耗尽或达到回调限制时,事件循环将移至下一阶段,依此类推。
由于这些操作中的任何一个可以调度更多操作,并且在轮询阶段中处理的新事件由内核排队,因此轮询事件可以在处理轮询事件时排队。因此,长时间运行的回调可以允许轮询阶段运行的时间比计时器的阈值长得多
注意:Windows和Unix/Linux实现之间存在轻微差异,但这对于此演示并不重要。最重要的部分在这里。实际上有七到八个步骤,而我们关心的是 - Node.js实际使用的那些 - 是上面那些。
阶段概述
nodejs的事件循环分为6个阶段
- 计时器(
timers):此阶段执行setTimeout()和setInterval()调度的回调。 - 等待回调(
pending callbacks):执行延迟到下一个循环迭代的I/O回调 - 空闲,准备(
idle, prepare):仅在内部使用 - 轮询(
poll):检索新的I/O事件;执行与I/O相关的回调(几乎所有回调都是关闭回调,定时器和setImmediate()调度的回调);node将在适当的时候阻止 check:setImmediate()在这里调用回调- 关闭回调(
close callbacks):一些关闭回调,例如socket.on(’close’,…)
在事件循环的每次运行之间,Node.js检查它是否在等待任何异步的I/O或定时器,如果没有,则关闭。
代码片段:
1 | setTimeout(() => console.log("setTimeout",1)) |
循环阶段详情
计时器(timers)
计时器指定阈值,在该阈值之后可以执行提供的回调而不是人们希望它执行的确切时间。 定时器回调将在指定的时间过去后尽早安排; 但是,操作系统调度或其他回调的运行可能会延迟它们。
注意:从技术上讲,轮询阶段控制何时执行定时器。
例如,假设您计划在100毫秒阈值后执行超时,那么您的脚本将异步读取一个耗时95毫秒的文件:
1 | const fs = require('fs'); |
当事件循环进入轮询阶段时,它有一个空队列(fs.readFile()尚未完成),因此它将等待剩余的ms数,直到达到最快的计时器阈值。 当它等待95毫秒传递时,fs.readFile()完成读取文件,并且其完成需要10毫秒的回调被添加到轮询队列并执行。 当回调结束时,队列中不再有回调,因此事件循环将看到已达到最快定时器的阈值,然后回绕到定时器阶段以执行定时器的回调。 在此示例中,您将看到正在调度的计时器与正在执行的回调之间的总延迟将为105毫秒。
注意:为了防止轮询阶段使事件循环挨饿,libuv(实现Node.js事件循环的C库和平台的所有异步行为)在停止轮询更多的事件之前具有硬性最大值(取决于系统)。
等待回调(pending callbacks)
此阶段执行某些系统操作(例如TCP错误类型)的回调。 例如,如果TCP套接字在尝试连接时收到拒绝ECONNREFUSED,则某些*nix系统希望等待报告错误。 这将排队等待在挂起的回调阶段执行。
轮询(poll)
轮询阶段有两个主要功能:
- 计算它应该阻止和轮询
I/O的时间,然后 - 处理轮询队列中的事件。
当事件循环进入轮询阶段并且没有计划定时器时,将发生以下两种情况之一:
- 如果轮询队列不为空,则事件循环将遍历其同步执行它们的回调队列,直到队列已用尽或者达到系统相关的硬性限制。
- 如果轮询队列为空,则会发生以下两种情况之一:
- 如果
setImmediate()已调度脚本,则事件循环将结束轮询阶段并继续执行检查阶段以执行这些调度脚本。 - 如果
setImmediate()尚未调度脚本,则事件循环将等待将回调添加到队列,然后立即执行它们。
- 如果
轮询队列为空后,事件循环将检查已达到时间阈值的计时器。 如果一个或多个计时器准备就绪,事件循环将回绕到计时器阶段以执行那些计时器的回调。
check
此阶段允许人员在轮询阶段完成后立即执行回调。 如果轮询阶段变为空闲并且脚本已使用setImmediate()排队,则事件循环可以继续到检查阶段而不是等待。
setImmediate()实际上是一个特殊的计时器,它在事件循环的一个单独阶段运行。 它使用libuv API来调度,在轮询阶段完成后执行的回调。
通常,在执行代码时,事件循环最终会到达轮询阶段,它将等待传入连接,请求等。但是,如果已使用setImmediate()调度回调并且轮询阶段变为空闲,则将结束并继续检查阶段,而不是等待轮询事件。
关闭回调close callbacks
如果套接字或句柄突然关闭(例如socket.destroy()),则在此阶段将发出close事件。 否则它将通过process.nextTick()发出。
setImmediate() 与 setTimeout()
setImmediate和setTimeout()类似,但根据它们的调用时间以不同的方式运行。
setImmediate()用于在当前轮询阶段完成后执行脚本,即check阶段。setTimeout()计划在经过最小阈值(以ms为单位)后运行的脚本。
执行定时器的顺序将根据调用它们的上下文而有所不同。 如果从主模块中调用两者,则时间将受到进程性能的限制(可能受到计算机上运行的其他应用程序的影响)。
例如,如果我们运行不在I/O周期内的以下脚本(即主模块),则执行两个定时器的顺序是不确定的,因为它受进程性能的约束:
1 | // timeout_vs_immediate.js |
输出的顺序不确定:
1 | $ node timeout_vs_immediate.js |
但是,如果在I/O周期内移动两个调用,则始终首先执行立即回调:
1 | const fs = require('fs'); |
始终首先执行立即回调immediate,再执行setTimeout
1 | $ node timeout_vs_immediate.js |
使用setImmediate()而不是setTimeout()的主要优点是setImmediate()将始终在任何定时器之前执行(如果在I/O周期内调度),与存在多少定时器无关。
process.nextTick()
了解process.nextTick()
您可能已经注意到process.nextTick()没有显示在图中,即使它是异步API的一部分。 这是因为process.nextTick在技术上不是事件循环的一部分。 相反,nextTickQueue将在当前操作完成后处理,而不管事件循环的当前阶段如何。
回顾一下上面的图表,无论何时在给定阶段调用process.nextTick(),传递给process.nextTick()的所有回调都将在事件循环继续之前得到解决。 这可能会产生一些不好的情况,因为它允许您通过进行递归的process.nextTick()调用来饿死(starve)您的I/O,这会阻止事件循环到达轮询阶段。
为什么会被允许
为什么这样的东西会被包含在Node.js中? 其中一部分是一种设计理念,其中API应该始终是异步的,即使它不是必须的。 以下面代码段为例:
1 | function apiCall(arg, callback) { |
代码片段进行参数检查,如果不正确,它会将错误传递给回调。这个API最近更新了,允许将参数传递给process.nextTick(),允许它将回调后传递的任何参数作为参数传播到回调,因此您不必嵌套函数。
我们正在做的是将错误传回给用户,但只有在我们允许其余的用户代码执行之后。 通过使用process.nextTick,我们保证apiCall()始终在用户代码的其余部分之后和允许事件循环继续之前运行其回调。 为了实现这一点,允许JS调用堆栈展开然后立即执行提供的回调,这允许一个人对process.nextTick()进行递归调用而不会达到RangeError:超出v8的最大调用堆栈大小。
这种理念可能会导致一些潜在的问题,以以下片段为例:
1 | let bar; |
用户将someAsyncApiCall()定义为具有异步签名,但它实际上是同步操作的。 调用它时,在事件循环的同一阶段调用提供给someAsyncApiCall()的回调,因为someAsyncApiCall()实际上不会异步执行任何操作。 因此,回调尝试引用bar,即使它在范围内可能没有该变量,因为该脚本无法运行完成。
通过将回调放在process.nextTick()中,脚本仍然能够运行完成,允许在调用回调之前初始化所有变量,函数等。 它还具有不允许事件循环继续的优点。 在允许事件循环继续之前,向用户警告错误可能是有用的。
以下是使用process.nextTick()的前一个示例:
1 | let bar; |
这是另一个例子:
1 | const net = require("net") |
仅传递端口时,端口立即绑定。 因此可以立即调用listen回调。 问题是那时候不会设置.on('listen')。
为了解决这个问题,listening事件在nextTick中排队,以允许脚本运行完成。 这允许用户设置他们想要的任何事件处理程序。
process.nextTick() vs setImmediate()
就用户而言,我们有两个类似的调用,但它们的名称令人困惑。
process.nextTick()在同一阶段立即触发setImmediate()触发事件循环的后续迭代或tick
本质上,这些名字应该被交换。与setimmediation()相比,process.nextTick()更快速地触发,但这是过去的产物,不太可能改变。这样做会破坏npm上的大部分包。每天都有更多的新模块被添加,这意味着我们每天都在等待,更多的潜在故障发生。虽然它们令人困惑,但名称本身不会改变。
建议开发人员在所有情况下都使用setimmediation(),因为这样做更容易理解(而且会导致代码与更广泛的环境兼容,比如浏览器JS)。
为什么使用process.nextTick()
主要有两个原因:
- 允许用户处理错误,清除任何不需要的资源,或者在事件循环继续之前再次尝试请求。
- 有时需要允许回调在调用堆栈展开之后但在事件循环继续之前运行。
一个例子简单的例子:
1 | const net = require("net") |
假设listen()在事件循环的开头运行,但是侦听回调被放置在setimmediation()中。现在,除非将主机名传递给端口,否则绑定将立即发生。现在,为了让事件循环继续进行,它必须到达轮询阶段,这意味着有一个非零的机会,连接可能已经收到,允许连接事件在侦听事件之前被触发。
另一个例子是运行一个函数构造函数,比如继承自EventEmitter,它想在构造函数中调用一个事件:
1 | const EventEmitter = require('events'); |
您无法立即从构造函数中发出事件,因为脚本将不会处理到用户为该事件分配回调的位置。 因此,在构造函数本身中,您可以使用process.nextTick()来设置回调以在构造函数完成后发出事件,从而提供预期的结果:
1 | const EventEmitter = require('events'); |
libuv
libuv是最初为NodeJS编写的跨平台支持库。 它是围绕事件驱动的异步I/O模型设计的。
I/O(或事件)循环
I/O(或事件)循环是libuv的中心部分。它为所有I/O操作建立内容,并且它被绑定到一个线程。只要在不同的线程中运行,就可以运行多个事件循环。libuv事件循环(或任何其他涉及循环或句柄的API)不是线程安全的,除非另有说明。
为了更好地理解事件循环的运行方式,下图说明了循环迭代的所有阶段:

重要: 虽然 libuv 的异步文件 I/O操作是通过线程池实现的,但是网络 I/O 总是在单线程中执行的。
相关链接
- 事件循环Event loop
- WHATWG规范对Event loop
- 并发模型与事件循环
- 任务,微任务,队列和日程安排
The Node.js Event Loop, Timers, and process.nextTick()- 不要混淆nodejs和浏览器中的event loop
- 跨平台异步I/O. libuv
- Event loop in JavaScript
- 使用 Google V8 引擎开发可定制的应用程序
- 深入理解Nodejs核心思想与源码分析基于node v6.0.0
- node源码粗读系列文章
- process.nextTick(callback[, …args])
- libuv 设计概述
- 在运行时可视化
javascript运行时